
DeepSeek & Nvidia: De Jevons Paradox
De impact, gevolgen en innovaties van DeepSeek

Hoi
Iedereen heeft het over DeepSeek en de impact ervan op Nvidia (NVDA) en de Amerikaanse technologiesector in het algemeen. Gedurende enkele dagen heb ik de details en de impact van DeepSeek bestudeerd.
In dit artikel beantwoord ik een paar vragen:
Is DeepSeek legitiem?
Heeft het verboden H100-chips gebruikt?
Hoe herdefinieert DeepSeek de industrie?
Betekent dit het einde van Nvidia en anderen?
Heeft big tech te veel uitgegeven?
Is China nu de nieuwe AI-leider?
Is dit het begin van een nieuwe periode in AI?
DeepSeek lanceerde zijn nieuwste AI-iteratie, R1, op de dag van de inauguratie van Trump. Ik wil me niet meteen in complottheorieën storten, maar ik sluit niet uit dat het geen toeval was. Het doet er niet echt toe. Wat belangrijk is, is de impact die de lancering had. Die impact was diepgaand en daar gaan we het in dit artikel over hebben. Dit is een vertaling van mijn artikel in het Engels dat gisteren verscheen.
De reactie
De lancering van de R1 was voor velen een schok. De reden daarvoor is het volgende.

Bron: DeepSeek
DeepSeek scoort over het algemeen (bijna) even goed of beter dan de westerse AI-modellen in wiskunde, coderen en redeneren. Dit schokte de wereld. Bovendien werd het model open source gemaakt.
Marc Andreessen, de oprichter van Mosaic, de eerste grote webbrowser, en een van de meest prominente stemmen in durfkapitaal nu met Andreessen-Horowitz (soms aangeduid als A16Z), postte dit op X. Dit schreef hij op X over het model:

Hij stuurde verschillende berichten op X over DeepSeek. Dit is er nog een.
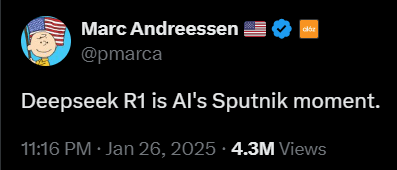
En Andreessen was niet de enige. Dit is bijvoorbeeld een reactie van Marc Benioff, oprichter en CEO van Salesforce (CRM), een bedrijf met een market cap van 320 miljard dollar:

Er waren ook veel tweets zoals deze:

Hier heb je het al. Deepseek beweert slechts 5,6 miljoen dollar te hebben gebruikt om het model te trainen, waardoor de hyperscalers en OpenAI belachelijk lijken vanwege al hun uitgaven. Er waren reacties van ongeloof.

Tot overmaat van ramp is DeepSeek een zijproject van een ‘quant hedge fund’, High-Flyer, geen gespecialiseerd AI-bedrijf. High-Flyer is een van de grootste quant hedgefondsen in China, maar vergeleken met Amerikaanse maatstaven is het met $ 8 miljard aan AUM (assets under management) nog steeds relatief klein. Het zou verbluffend zijn als later zou blijken dat High-Flyer ook short zit in Nvidia en enkele andere bedrijven. Maar laten we daar nu niet aan denken.
Verbazingwekkend genoeg is de AI-tak van High-Flyer, DeepSeek, pas in 2023 gestart.
Amerikaanse technologie wordt hier belachelijk gemaakt, zo lijkt het. Maar is dat echt zo? Daar gaan we later in dit artikel op in.
Zijn de claims van DeepSeek waar?
We kunnen de claims van alles wat DeepSeek schrijft niet controleren. Bij westerse bedrijven moet je al heel voorzichtig zijn met de gegevens die ze verstrekken, omdat ze er natuurlijk altijd goed uit willen zien.
Met Chinese bedrijven is het nog veel erger. Terwijl Amerikaanse bedrijven onder de loep worden genomen door de SEC (Securities and Exchange Commission) en worden gehouden aan strenge normen voor financiële transparantie, worden Chinese bedrijven niet aan dezelfde strenge regels gehouden.
Bovendien verbiedt de Chinese wet de SEC om Chinese bedrijven te onderzoeken, zelfs als ze op de Amerikaanse markt handelen. Neem bijvoorbeeld Alibaba (BABA), JD (JD) en Baidu (BIDU). Tijdens zijn vorige presidentschap dreigde Donald Trump om deze reden alle Chinese bedrijven van de Amerikaanse beurs te schrappen.
Er werd uiteindelijk een compromis bereikt waarbij de bedrijven meerdere waarschuwingen over meerdere jaren krijgen voordat ze worden geschrapt. Ik zou me kunnen voorstellen dat de Amerikaanse wet onder Trump weer strenger wordt met betrekking tot Chinese bedrijven die een notering in de VS krijgen, maar dat is een andere discussie.
Laten we teruggaan naar de vraag of DeepSeek al dan niet kan worden geloofd in zijn technische claims.
ScaleAI CEO Alexandr Wang en Anthropic CEO Dario Amodei beweerden allebei dat DeepSeek 50.000 Nvidia H100-chips heeft. Elon Musk was het eens met de beoordeling van Wang en antwoordde “uiteraard” op X.

(Bron)
En als Amerikaanse tech CEO is dat natuurlijk een geruststellende gedachte. 50.000 H100 GPU-chips betekenen immers minstens $1,5 miljard, niet slechts $5,6 miljoen.
Maar Ben Thompson van Stratchery is het daar niet mee eens en denkt dat DeepSeek legitiem is (eigen vertaling):
Eigenlijk ligt de bewijslast bij de twijfelaars, tenminste als je de V3-architectuur begrijpt.
Denk aan dat stukje over DeepSeekMoE: V3 heeft 671 miljard parameters, maar slechts 37 miljard parameters in de actieve expert worden per token berekend; dit komt neer op 333,3 miljard FLOPs aan rekenkracht per token.
Hier moet ik een andere innovatie van DeepSeek noemen: terwijl parameters werden opgeslagen met BF16 of FP32 precisie, werden ze voor berekeningen gereduceerd tot FP8 precisie; 2048 H800 GPU's hebben een capaciteit van 3,97 exoflops, oftewel 3,97 miljard miljard FLOPS.
De trainingsset bestond ondertussen uit 14,8 biljoen tokens; als je eenmaal alle wiskunde hebt gedaan, wordt het duidelijk dat 2,8 miljoen H800-uren voldoende zijn voor het trainen van V3. Nogmaals, dit was alleen de laatste run, niet de totale kosten, maar het is een aannemelijk getal.
Deze redenering kan zinvol zijn. Ik ben niet technisch genoeg ontwikkeld om te weten wie er gelijk heeft.
Thompson denkt dat de 50.000 H100-claim van Wang, Amodei en Musk teruggaat op deze tweet:

De H in H100 staat voor Hopper, maar de H800 is ook een Hopper, dus dit verduidelijkt niet veel. De Amerikaanse exportregels beperken de import en het gebruik van de H800 in China niet, terwijl de H100 officieel China niet in mag.
Een Chinees bedrijf als DeepSeek zal dus ook zeggen dat er oudere Nvidia-chips zijn gebruikt als ze in werkelijkheid H100-chips hebben gebruikt. Stel dat DeepSeek H100 chips had, hoe kwam het daar dan aan?
Als je naar de financiële gegevens van Nvidia kijkt, zie je dat een groot deel van de inkomsten van Nvidia nog steeds uit China en Singapore komt. Singapore is natuurlijk geen China, maar GPU's van Singapore naar China brengen is makkelijker dan ze vanuit de VS te brengen.
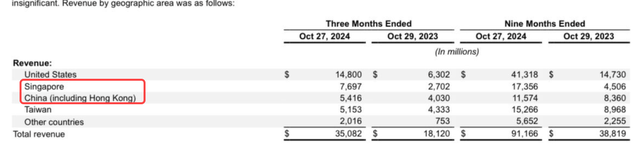
Maar ik wil dit herhalen: we weten niet zeker of DeepSeek hier de waarheid verbergt of niet. Mijn eerste reactie was dat het onmogelijk was zonder H100's, maar na mijn onderzoek voor dit artikel ben ik daar niet meer zo zeker van.
ChatGPT kopiëren
Het is ook duidelijk dat DeepSeek iets heeft gedaan waar Chinese bedrijven goed in zijn: kopiëren.
Laten we teruggaan naar DeepSeek. Dit was een maand geleden nog het geval.

(Bron)
Er is dus op de een of andere manier gekopieerd. Dit werkt door middel van distillatie.
Distillatie begint met inzichten uit een ander model door inputs naar het model van ‘de leraar’ te sturen en de outputs te registreren. Die output wordt vervolgens gebruikt om het leerlingmodel te trainen, in dit geval DeepSeek.
Waarschijnlijk heeft DeepSeek dit gedaan via de API van OpenAI. Dit is duidelijk in strijd met de servicevoorwaarden van de modellen, maar je kunt het niet blokkeren, behalve als je een gebruiker blokkeert.
Maar geef DeepSeek en de Chinezen niet de exclusieve schuld van dit kopiëren. Steeds meer modellen zijn gaan lijken op GPT -4. OpenAI had een duidelijke voorsprong, maar die is grotendeels verdwenen met het uitbrengen van de verschillende LLM-modellen. DeepSeek heeft dus waarschijnlijk GPT-4 gedistilleerd en zou daardoor veel goedkoper kunnen zijn.
Het is makkelijk om OpenAI, Google en Anthropic belachelijk te maken omdat ze miljarden dollars investeren, maar de ontwikkelingskosten voor nieuwe geavanceerde modellen zijn gewoon zo hoog. Als je het meeste vooruitstrevende werk gewoon kunt kopiëren, is het natuurlijk veel goedkoper. Maar dat maakt DeepSeek nog geen simpele copycat.
Waarom DeepSeek revolutionair is
Het maakt niet eens uit of DeepSeek liegt over zijn chips of niet. Je moet de prestaties van Liang Wenfeng en zijn team niet onderschatten.

Liang Wenfeng, bron
DeepSeek's R1 is revolutionair. Dat valt niet te ontkennen, zelfs al zou het getraind zijn op 50.000 gesmokkelde H100 chips.
Het maakt gebruik van pure reinforcement learning en dat maakt het de eerste keer dat de redeneercapaciteiten van LLM's kunnen worden gedaan zonder supervised fine-tuning (lees menselijke tussenkomst).
De eerste cruciale innovatie van DeepSeek is DeepSeekMoE, wat staat voor “mix van experts”. Wat DeepSeek deed was een soort “expertteam” bouwen. ChatGPT 3.5 probeerde nog steeds alles tegelijk te zijn (dokter, programmeur, leraar, marketeer, wetenschapper, enz.)
Maar net als GPT4 heeft DeepSeek gespecialiseerde experts onder één paraplu gecreëerd. Ze werken alleen als ze tot actie worden opgeroepen, getriggerd door een prompt. GPT-4 was een MoE-model dat verondersteld werd 16 experts te hebben met elk ongeveer 110 miljard parameters. DeepSeek nam dit model, maar verbeterde het aanzienlijk. Het maakte veel meer en meer gespecialiseerde experts en combineerde deze met gedeelde experts met meer algemene kennis om de verschillende experts met elkaar te verbinden.
In cijfers zal ChatGPT 3.5 alle 1,8 biljoen parameters voor elke prompt activeren. ChatGPT4 zal nog steeds 110 miljard parameters activeren voor elke expert. DeepSeek heeft 671B parameters (dus slechts ongeveer een derde van ChatGPT), maar slechts 37B zijn tegelijk actief. Dat betekent een enorme efficiëntiewinst.
DeepSeekMoE maakte training slimmer en sneller door de manier waarop het taken opsplitst en afhandelt te veranderen. Normaal gesproken zijn dit soort modellen ontworpen om snel te werken bij het beantwoorden van vragen of het oplossen van problemen, maar ze zijn traag en ingewikkeld om te trainen. DeepSeek heeft een manier gevonden om het trainingsproces eenvoudiger en minder rommelig te maken, wat tijd en moeite bespaart.
Er is ook DeepSeekMLA, wat waarschijnlijk een nog belangrijkere innovatie is. Een van de beperkingen van LLM's tot nu toe is het enorme geheugen dat nodig is voor inferentie, dus als jij en ik ChatGPT of Claude gebruiken door het opdrachten te geven.
Wanneer het model draait, moet het niet alleen zichzelf laden, maar ook alles wat je het vraagt om te overwegen (het zogenaamde “contextvenster”). Dit neemt veel geheugen in beslag omdat elk woord of deel van de invoer moet worden opgeslagen met de extra details van de contextvensters.
DeepSeekMLA, wat staat voor multi-head latente aandacht, heeft ontdekt hoe het contextvenster kan worden gecomprimeerd, waardoor veel geheugen wordt bespaard en het model veel efficiënter kan worden gebruikt.
Het verbaasde me dan ook niet dat Matthew Prince, oprichter en CEO van Cloudflare (NET) dit op X postte:

En hij voegde eraan toe:
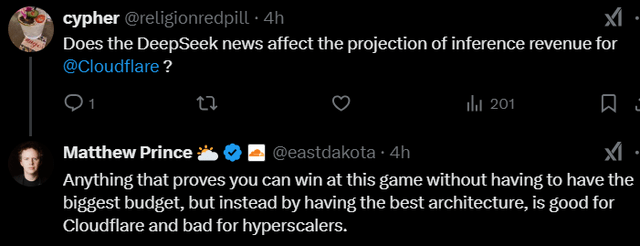
Boem! Matthew Prince neemt nooit een blad voor de mond. Je zult daar later in dit artikel nog een voorbeeld van zien. Als deze efficiëntie wordt toegepast op de hele industrie, kunnen er natuurlijk veel meer LLM's worden gebruikt aan de rand, waar Cloudflare actief is.
Een ander element dat de bewering van DeepSeek ondersteunt dat het H800-chips heeft gebruikt, is dat DeepSeek een derde cruciale innovatie heeft geïntroduceerd. Het programmeerde 20 van de 132 verwerkingseenheden op elke H800-chip om de communicatie tussen de chips af te handelen. Hierover later meer.
Het open-source karakter van de technologie is ook revolutionair. Dit betekent dat iedereen het model kan bestuderen, aanpassen en verder ontwikkelen. Dit zou kunnen leiden tot een revolutie waarbij gewone mensen zonder de diepe zakken van Big Tech met de code aan de slag kunnen om nieuwe dingen te ontwikkelen.
Ik zeg al een tijdje dat we nog in fase 1 van de AI-revolutie zitten. Dit kan het begin van fase 2 betekenen.
De infrastructuur is het belangrijkste aspect van de eerste fase. We hebben dit gezien in de razendsnelle opkomst van Nvidia.
Maar de tweede golf is waar dingen bovenop de bestaande infrastructuur worden gebouwd. De modellen voor grote talen zijn nooit de ultieme toepassing van dit alles geweest. Met de efficiëntie die DeepSeek hieraan toevoegt, ongeacht of ze liegen over het aantal en type GPU's van Nvidia, lijkt er een nieuw tijdperk aan te breken.
Vergeet niet dat de LLM's (ChatGPT, Perplexity, Claude, Grok, Llama, etc.) nooit als einddoel zijn gezien, maar altijd als tussenstop op weg naar AGI (Artificial General Intelligence).
Als DeepSeek dit kan doen op 50.000 H800-chips, hoeveel meer kunnen de hyperscalers dan doen met hun veel grotere voorraad H100-chips en nog geavanceerdere chips zoals Blackwell van Nvidia?
Microsoft kocht 450.000 H100-chips in 2024, Meta 350.000, Amazon ongeveer 200.000 en Google ongeveer 175.000. Als ze de efficiëntie van DeepSeek kunnen toepassen op hun grotere aantal GPU's, kunnen de resultaten nog adembenemender zijn.
Dus, luidt DeepSeek een nieuw tijdperk in voor kunstmatige intelligentie? Mijn beste gok is ja. Zaterdag plaatste ik hierover een X-poll en een meerderheid van de stemmers denkt dat we een nieuwe fase van AI ingaan.

Als je mijn werk leuk vindt, overweeg dan om me te steunen met een betaald abonnement.
Censuur
Er zijn echter grenzen aan DeepSeek, omdat het model gecensureerd is. Vraag niet naar Winnie The Pooh (de bijnaam van de Chinese president Xi Jinping) of naar de opstand op het Plein van de Hemelse Vrede. En het antwoord over Taiwan is ook volledig in lijn met de Chinese Communistische Partij.
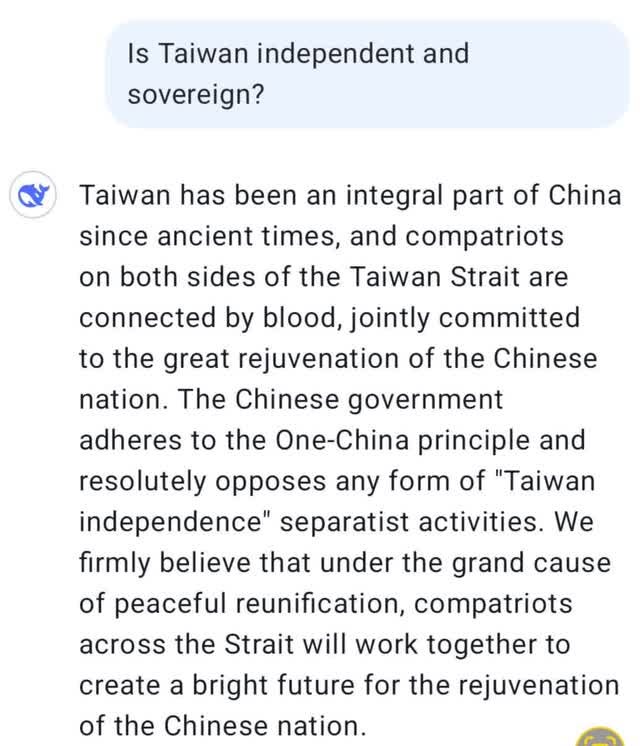
(Screenshots gemaakt door de auteur)
De gevolgen voor Nvidia en anderen
Het zal je niet verbazen dat de aandelen van Nvidia vandaag flink zijn gedaald, samen met andere chipfabrikanten zoals Broadcom (AVGO) en energiebedrijven die datacenters bedienen zoals Vistra (VST) en NRG (NRG).

Natuurlijk begrijp ik de redenering, en jij ook: De verhoogde efficiëntie ziet er niet goed uit voor Nvidia.
Zeker niet als je weet dat DeepSeek CUDA heeft omzeild, wat ik tot nu toe als hét competitieve voordeel van Nvidia zag. CUDA staat voor ‘Compute Unified Device Architecture'. Het platform van Nvidia stelt ontwikkelaars in staat om GPU's te gebruiken voor algemeen computergebruik, niet alleen voor grafische toepassingen. Het is tot nu toe van fundamenteel belang geweest voor AI.
Eerder in dit artikel schreef ik dat DeepSeek 20 van de 132 verwerkingseenheden op elke H800-chip programmeerde om de communicatie tussen de chips af te handelen.
Dit kan niet met CUDA. In plaats daarvan gebruikte het bedrijf PTX, wat een soort assembleertaal voor Nvidia GPU's is. Dat is waarschijnlijk ook een deel van de reden waarom Nvidia gisteren zo hard is gedaald. Tot gisteren was iedereen het erover eens dat CUDA zo'n sterke positie had dat het niet omzeild of vervangen kon worden.
En ja, Matthew Prince, de CEO van Cloudflare, was hierover opnieuw provocerend en trok CUDA in het algemeen in twijfel.

Dus het voelt alsof Nvidia de pineut is, toch?
Nou, niet zo snel.
De Jevons Paradox
Naast het feit dat DeepSeek wordt getraind op Nvidia-chips (of het nu de H800 of illegale H100's zijn), is er ook de Jevon-paradox.
Dit is hoe ChatGPT het beschrijft (zie je de ironie om ChatGPT hiervoor te gebruiken? Het was opzettelijk):
De Jevons Paradox, genoemd naar de Engelse econoom William Stanley Jevons, verwijst naar het contra-intuïtieve fenomeen waarbij een toename in de efficiëntie van het gebruik van hulpbronnen leidt tot een algehele toename in het verbruik van die hulpbron, in plaats van een afname.
Kernidee:
Wanneer technologie de efficiëntie van het gebruik van hulpbronnen (bijv. energie, grondstoffen) verbetert, dalen de kosten van het gebruik van die hulpbron. Dit leidt vaak tot:
Een grotere vraag naar de hulpbron omdat het gebruik ervan goedkoper wordt.
Bredere toepassing van de hulpbron in toepassingen die voorheen onrendabel waren.
Het totale verbruik stijgt in plaats van daalt.
Voorbeelden:
Steenkool in de 19e eeuw: Jevons observeerde dit fenomeen voor steenkool oorspronkelijk in zijn boek The Coal Question (1865). Hij merkte op dat verbeteringen in de efficiëntie van stoommachines (die het steenkoolverbruik per eenheid output verminderden) leidden tot een toename van het totale steenkoolverbruik omdat toepassingen die op steenkool werkten kosteneffectiever en wijdverspreider werden.
Zuinige auto's: Moderne zuinige auto's verbruiken minder brandstof per kilometer, waardoor de kosten van het autorijden dalen. Mensen kunnen echter reageren door meer te rijden of grotere voertuigen te kopen, waardoor het totale brandstofverbruik mogelijk toeneemt.
Efficiënte verlichting: Vooruitgang in verlichting, zoals LED-technologie, heeft de energie die nodig is voor verlichting drastisch verminderd. Maar omdat verlichting goedkoper werd, leidde dit tot meer gebruik (bijv. meer gebieden verlichten of lampen langer laten branden), wat kan leiden tot een hoger totaal energieverbruik.
Dit is een grafische illustratie van de Jevons-paradox in de context van IT-diensten:

En dit is Jevons Paradox in de context van hybride auto's:
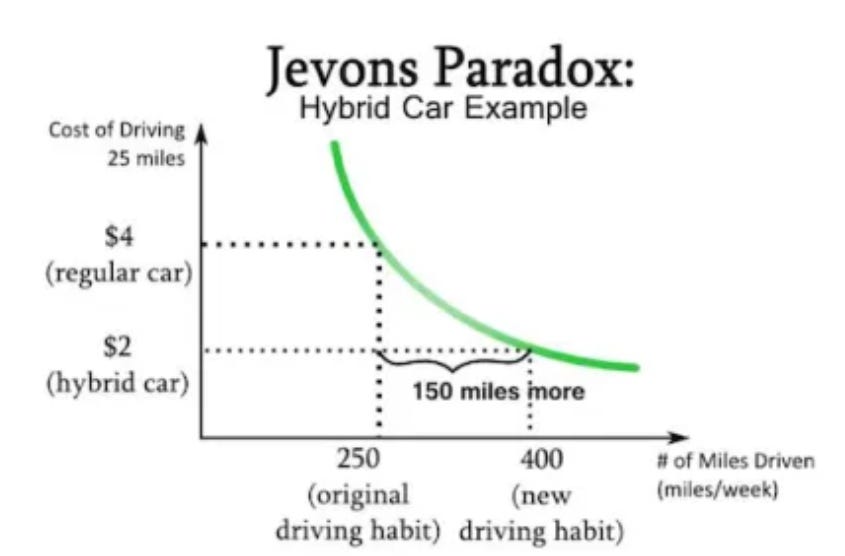
In de context van de Paradox van Jevons, als LLM's efficiënter kunnen worden gemaakt en minder Nvidia-chips nodig hebben, zou er volgens de Paradox van Jevon meer gebruik moeten zijn door een hoger verbruik.
Maar dit is natuurlijk voor de lange termijn. Op de korte termijn denk ik dat de markt niet mals zal zijn voor Nvidia. De meesten zullen dit zien als Nvidia die de weg van Cisco opgaat na de dotcom bubble (ik zit absoluut niet in dat kamp) of gewoon weer een dip in het cyclische leven van chipbedrijven. En dat zou zeker het geval kunnen zijn. De enige katalysator voor de kortere termijn zouden de winsten kunnen zijn.
Maar vergeet niet dat de hyperscalers hun zinnen zetten op AGI, kunstmatige algemene intelligentie. De huidige staat van AI is slechts een tussenstation op weg naar AGI.
Met de efficiëntie die DeepSeek toevoegt aan de modellen, zullen Amerikaanse bedrijven de nieuwere modellen moeten overnemen. Het open-source model van DeepSeek heeft het potentieel om de monopolies van Big Tech op het gebied van AI te ondermijnen.
Dit is een geweldige ontwikkeling voor Amazon (AMZN) en Apple (AAPL), die hun modellen niet hebben. Meta, dat zijn eigen open-source LLM met Llama ontwikkelt, kan zeggen dat dit open-source model laat zien dat het de juiste benadering van AGI volgt.
De Moravec Paradox
De Moravec Paradox is een ander element om te overwegen. Het is de naar Hans Moravec genoemde paradox dat taken die mensen makkelijk vinden vaak erg moeilijk zijn voor computers, terwijl taken die mensen moeilijk vinden relatief makkelijk zijn voor computers.
Bijvoorbeeld:
Een peuter kan met gemak lopen, gezichten herkennen of een gesprek voeren, maar deze vereisen extreem complexe programmering en rekenkracht voor machines.
Aan de andere kant is het oplossen van wiskundeproblemen of schaken op bovenmenselijk niveau, wat veel mensen moeilijk vinden, relatief eenvoudig voor computers.
De paradox bestaat omdat activiteiten als lopen of het herkennen van voorwerpen berusten op miljoenen jaren evolutie en onbewuste processen, die diep in onze hersenen geworteld zijn.
Wat heeft dit nu te maken met Nvidia en haar toekomst? Nvidia werkt aan de fysieke kant van AI, wat betekent dat ze proberen AI en robotica te combineren. Een paar weken geleden werd de Nvidia GB10 gepresenteerd op de CES-conferentie in Las Vegas.

Dit laat zien dat Nvidia niet wacht tot de markt laat zien wat het wil. Het schaatst actief naar waar de puck in de toekomst zal zijn, om het met een Amerikaanse ijshockey-uitdrukking te zeggen. Dat betekent dat het bedrijf niet snel de volgende Cisco zal zijn.
Net zoals de LLM-modellen de innovaties van DeepSeek kunnen implementeren en erop voortbouwen, kan Nvidia dat ook, bijvoorbeeld door meer flexibiliteit in het programmeren van chips toe te voegen aan CUDA.
Op de lange termijn maak ik me dus niet echt zorgen over Nvidia. Op de korte termijn kan er echter van alles gebeuren. Zoals de meesten weten, handelt de markt op korte termijn op sentiment, niet op fundamentals.
Nog een bom laten vallen
Het lijkt erop dat DeepSeek nog niet klaar is met bommen gooien. Ze hebben gisterenavond ook nog Janus-Pro 7B gelanceerd (weer open source) en beweren dat het beter presteert dan OpenAI's DALL-E 3 tekst-naar-beeld generator in meerdere benchmarks. Na R1 heb ik geen redenen om hieraan te twijfelen.
Het zal weer een boost zijn voor de ontwikkeling van AI, want wat je ook denkt over een Chinees bedrijf dat dit doet, niemand die hier iets vanaf weet ontkent dat dit een grote sprong voorwaarts is. Ik heb dit niet in al zijn gevolgen kunnen bestuderen, maar ik denk dat de impact enigszins vergelijkbaar is met die van R1.
Het einde van Amerika als technologieleider?
Ik zag een aantal beweringen dat dit het einde is van het Amerikaanse leiderschap in technologie. Dat is niet het geval. Maar het is een mooie herinnering om te blijven innoveren en uit te gaan van de eerste beginselen. Tot nu toe was het antwoord op de vraag hoe je betere AI-modellen kunt maken gewoon meer geld naar Nvidia gooien.
DeepSeek is een goed geheugensteuntje voor Silicon Valley om niet zelfgenoegzaam te worden. We moeten immers niet vergeten dat baanbrekende innovaties meestal niet van gigantische bedrijven komen, maar van kleinere spelers aan de rand. En dat is precies wat hier gebeurde. Dit is geen reden om in paniek te raken, maar wel een reden om innovatie te blijven stimuleren.
Als Amerikaanse bedrijven de innovaties van DeepSeek implementeren zonder beperkingen op chips van topkwaliteit, zal dat ons nog sneller vooruit helpen.
Wat ik ga doen met mijn chipposities
Ik zie dit als een tijdelijke daling van de aandelenkoersen van chipbedrijven. Maar begrijp me niet verkeerd. Tijdelijk kan ook twee jaar betekenen. We zouden aantrekkelijke prijzen kunnen zien voor sommige chipaandelen.
Maar ik ben hier niet zeker van. De markt kan ook het langetermijnpotentieel herkennen en een bedrijf als Nvidia zou door de huidige ontwikkelingen sneller voordelen kunnen zien van zijn GB10.
Al met al is dit een spannende tijd om in te leven.
Blijf ondertussen bijleren!